Go 博客
The New Go Developer Network
2019/03/14
A sense of community flourishes when we come together in person. As handles become names and avatars become faces, the smiles are real and true friendship can grow. There is joy in the sharing of knowledge and celebrating the accomplishments of our friends, colleagues, and neighbors. In our rapidly growing Go community this critical role is played by the Go user groups.
To better support our Go user groups worldwide, the Go community leaders at GoBridge and Google have joined forces to create a new program called the Go Developer Network (GDN). The GDN is a collection of Go user groups working together with a shared mission to empower developer communities with the knowledge, experience, and wisdom to build the next generation of software in Go.
We have partnered with Meetup to create our own Pro Network of Go Developers providing Go developers a single place to search for local user groups, events, and see what other Gophers are doing around the world.
User groups that join the GDN will be recognized by GoBridge as the official user group for that city and be provided with the latest news, information, conduct policies, and procedures. GDN groups will have Meetup fees paid by the GDN and will have access to special swag and other fun items. Each organizer of a GDN local group will continue to own the group and maintain full admin rights. If you currently run a user group, please fill out this application to request to join the GDN.
We hope you are as excited about the GDN as we are.
What's new in the Go Cloud Development Kit
2019/03/04
Introduction
Last July, we introduced the Go Cloud Development Kit (previously referred to as simply "Go Cloud"), an open source project building libraries and tools to improve the experience of developing for the cloud with Go. We've made a lot of progress since then -- thank you to early contributors! We look forward to growing the Go CDK community of users and contributors, and are excited to work closely with early adopters.
Portable APIs
Our first initiative is a set of portable APIs for common cloud services. You write your application using these APIs, and then deploy it on any combination of providers, including AWS, GCP, Azure, on-premise, or on a single developer machine for testing. Additional providers can be added by implementing an interface.
These portable APIs are a great fit if any of the following are true:
- You develop cloud applications locally.
- You have on-premise applications that you want to run in the cloud (permanently, or as part of a migration).
- You want portability across multiple clouds.
- You are creating a new Go application that will use cloud services.
Unlike traditional approaches where you would need to write new application code for each cloud provider, with the Go CDK you write your application code once using our portable APIs to access the set of services listed below. Then, you can run your application on any supported cloud with minimal config changes.
Our current set of APIs includes:
- blob, for persistence of blob data. Supported providers include: AWS S3, Google Cloud Storage (GCS), Azure Storage, the filesystem, and in-memory.
- pubsub for publishing/subscribing of messages to a topic. Supported providers include: Amazon SNS/SQS, Google Pub/Sub, Azure Service Bus, RabbitMQ, and in-memory.
- runtimevar, for watching external configuration variables. Supported providers include AWS Parameter Store, Google Runtime Configurator, etcd, and the filesystem.
- secrets, for encryption/decryption. Supported providers include AWS KMS, GCP KMS, Hashicorp Vault, and local symmetric keys.
- Helpers for connecting to cloud SQL providers. Supported providers include AWS RDS and Google Cloud SQL.
- We are also working on a document storage API (e.g. MongoDB, DynamoDB, Firestore).
Feedback
We hope you're as excited about the Go CDK as we are -- check out our godoc, walk through our tutorial, and use the Go CDK in your application(s). We'd love to hear your ideas for other APIs and API providers you'd like to see.
If you're digging into Go CDK please share your experiences with us:
- What went well?
- Were there any pain points using the APIs?
- Are there any features missing in the API you used?
- Suggestions for documentation improvements.
To send feedback, you can:
- Submit issues to our public GitHub repository.
- Email go-cdk-feedback@google.com.
- Post to our public Google group.
Thanks!
Go 1.12 is released
2019/02/25
Today the Go team is happy to announce the release of Go 1.12. You can get it from the download page.
For details about the changes in Go 1.12, see the Go 1.12 release notes.
Some of the highlights include opt-in support for TLS 1.3, improved modules support (in preparation for being the default in Go 1.13), support for windows/arm, and improved macOS & iOS forwards compatibility.
As always, we also want to thank everyone who contributed to this release by writing code, filing bugs, providing feedback, and/or testing the betas and release candidates. Your contributions and diligence helped to ensure that Go 1.12 is as stable as possible. That said, if you do notice any problems, please file an issue.
Enjoy the new release!
Go Modules in 2019
2018/12/19
What a year!
2018 was a great year for the Go ecosystem, with package management as one of our major focuses. In February, we started a community-wide discussion about how to integrate package management directly into the Go toolchain, and in August we delivered the first rough implementation of that feature, called Go modules, in Go 1.11. The migration to Go modules will be the most far-reaching change for the Go ecosystem since Go 1. Converting the entire ecosystem—code, users, tools, and so on—from GOPATH to modules will require work in many different areas. The module system will in turn help us deliver better authentication and build speeds to the Go ecosystem.
This post is a preview of what the Go team is planning relating to modules in 2019.
Releases
Go 1.11, released in August 2018, introduced preliminary support for modules.
For now, module support is maintained alongside the
traditional GOPATH-based mechanisms.
The go command defaults to module mode when run
in directory trees outside GOPATH/src and
marked by go.mod files in their roots.
This setting can be overridden by setting the transitional
environment variable $GO111MODULE to on or off;
the default behavior is auto mode.
We’ve already seen significant adoption of modules across the Go community,
along with many helpful suggestions and bug reports
to help us improve modules.
Go 1.12, scheduled for February 2019, will refine module support
but still leave it in auto mode by default.
In addition to many bug fixes and other minor improvements,
perhaps the most significant change in Go 1.12
is that commands like go run x.go
or go get rsc.io/2fa@v1.1.0
can now operate in GO111MODULE=on mode without an explicit go.mod file.
Our aim is for Go 1.13, scheduled for August 2019, to enable module mode by
default (that is, to change the default from auto to on)
and deprecate GOPATH mode.
In order to do that, we’ve been working on better tooling support
along with better support for the open-source module ecosystem.
Tooling & IDE Integration
In the eight years that we’ve had GOPATH, an incredible amount of tooling has been created that assumes Go source code is stored in GOPATH. Moving to modules requires updating all code that makes that assumption. We’ve designed a new package, golang.org/x/tools/go/packages, that abstracts the operation of finding and loading information about the Go source code for a given target. This new package adapts automatically to both GOPATH and modules mode and is also extensible to tool-specific code layouts, such as the one used by Bazel. We’ve been working with tool authors throughout the Go community to help them adopt golang.org/x/tools/go/packages in their tools.
As part of this effort, we’ve also been working to unify the various source code querying tools like gocode, godef, and go-outline into a single tool that can be used from the command line and also supports the language server protocol used by modern IDEs.
The transition to modules and the changes in package loading
also prompted a significant change to Go program analysis.
As part of reworking go vet to support modules,
we introduced a generalized framework for incremental
analysis of Go programs,
in which an analyzer is invoked for one package at a time.
In this framework, the analysis of one package can write out facts
made available to analyses of other packages that import the first.
For example, go `vet`’s analysis of the log package
determines and records the fact that log.Printf is a fmt.Printf wrapper.
Then go vet can check printf-style format strings in other packages
that call log.Printf.
This framework should enable many new, sophisticated
program analysis tools to help developers find bugs earlier
and understand code better.
Module Index
One of the most important parts of the original design for go get
was that it was decentralized:
we believed then—and we still believe today—that
anyone should be able to publish their code on any server,
in contrast to central registries
such as Perl’s CPAN, Java’s Maven, or Node’s NPM.
Placing domain names at the start of the go get import space
reused an existing decentralized system
and avoided needing to solve anew the problems of
deciding who can use which names.
It also allowed companies to import code on private servers
alongside code from public servers.
It is critical to preserve this decentralization as we shift to Go modules.
Decentralization of Go’s dependencies has had many benefits, but it also brought a few significant drawbacks. The first is that it’s too hard to find all the publicly-available Go packages. Every site that wants to deliver information about packages has to do its own crawling, or else wait until a user asks about a particular package before fetching it.
We are working on a new service, the Go Module Index,
that will provide a public log of packages entering the Go ecosystem.
Sites like godoc.org and goreportcard.com will be able to watch this log
for new entries instead of each independently implementing code
to find new packages.
We also want the service to allow looking up packages
using simple queries, to allow goimports to add
imports for packages that have not yet been downloaded to the local system.
Module Authentication
Today, go get relies on connection-level authentication (HTTPS or SSH)
to check that it is talking to the right server to download code.
There is no additional check of the code itself,
leaving open the possibility of man-in-the-middle attacks
if the HTTPS or SSH mechanisms are compromised in some way.
Decentralization means that the code for a build is fetched
from many different servers, which means the build depends on
many systems to serve correct code.
The Go modules design improves code authentication by storing
a go.sum file in each module;
that file lists the cryptographic hash
of the expected file tree for each of the module’s dependencies.
When using modules, the go command uses go.sum to verify
that dependencies are bit-for-bit identical to the expected versions
before using them in a build.
But the go.sum file only lists hashes for the specific dependencies
used by that module.
If you are adding a new dependency
or updating dependencies with go get -u,
there is no corresponding entry in go.sum and therefore
no direct authentication of the downloaded bits.
For publicly-available modules, we intend to run a service we call a notary
that follows the module index log,
downloads new modules,
and cryptographically signs statements of the form
“module M at version V has file tree hash H.”
The notary service will publish all these notarized hashes
in a queryable, Certificate Transparency-style
tamper-proof log,
so that anyone can verify that the notary is behaving correctly.
This log will serve as a public, global go.sum file
that go get can use to authenticate modules
when adding or updating dependencies.
We are aiming to have the go command check notarized hashes
for publicly-available modules not already in go.sum
starting in Go 1.13.
Module Mirrors
Because the decentralized go get fetches code from multiple origin servers,
fetching code is only as fast and reliable as the slowest,
least reliable server.
The only defense available before modules was to vendor
dependencies into your own repositories.
While vendoring will continue to be supported,
we’d prefer a solution that works for all modules—not just the ones you’re already using—and
that does not require duplicating a dependency into every
repository that uses it.
The Go module design introduces the idea of a module proxy,
which is a server that the go command asks for modules,
instead of the origin servers.
One important kind of proxy is a module mirror,
which answers requests for modules by fetching them
from origin servers and then caching them for use in
future requests.
A well-run mirror should be fast and reliable
even when some origin servers have gone down.
We are planning to launch a mirror service for publicly-available modules in 2019.
Other projects, like GoCenter and Athens, are planning mirror services too.
(We anticipate that companies will have multiple options for running
their own internal mirrors as well, but this post is focusing on public mirrors.)
One potential problem with mirrors is that they are precisely man-in-the-middle servers, making them a natural target for attacks. Go developers need some assurance that the mirrors are providing the same bits that the origin servers would. The notary process we described in the previous section addresses exactly this concern, and it will apply to downloads using mirrors as well as downloads using origin servers. The mirrors themselves need not be trusted.
We are aiming to have the Google-run module mirror
ready to be used by default in the go command starting in Go 1.13.
Using an alternate mirror, or no mirror at all, will be trivial
to configure.
Module Discovery
Finally, we mentioned earlier that the module index will make it easier to build sites like godoc.org. Part of our work in 2019 will be a major revamp of godoc.org to make it more useful for developers who need to discover available modules and then decide whether to rely on a given module or not.
Big Picture
This diagram shows how module source code moves through the design in this post.
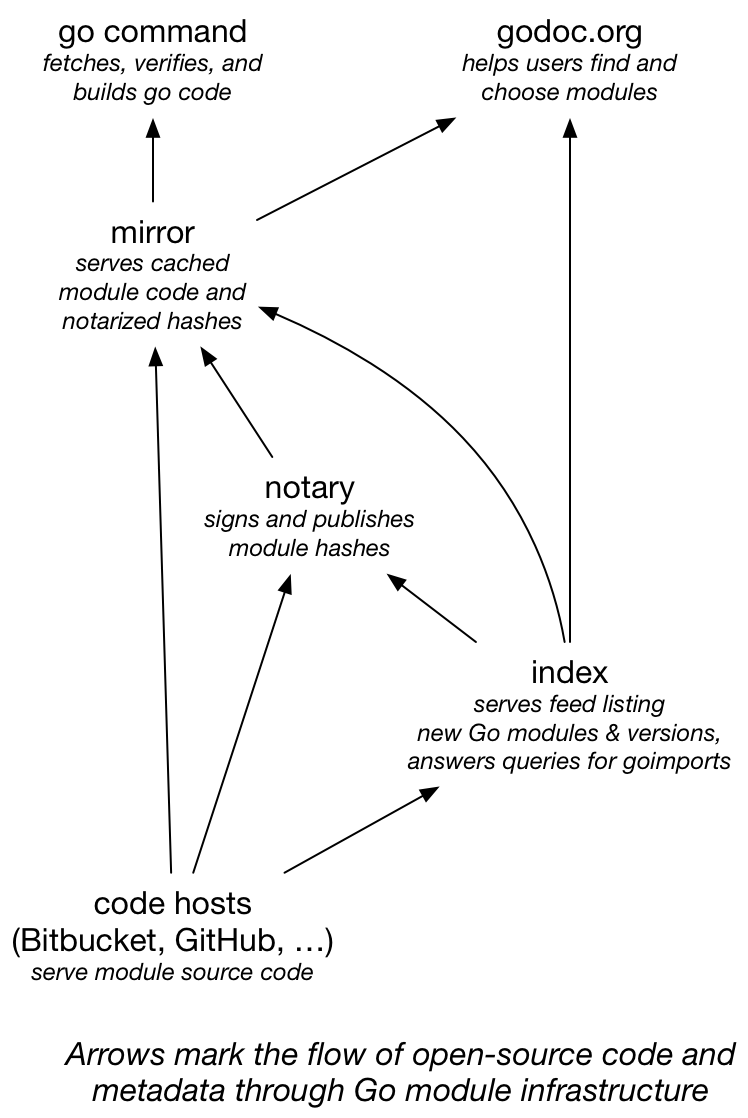
Before, all consumers of Go source code—the go command
and any sites like godoc.org—fetched code directly from each code host.
Now they can fetch cached code from a fast, reliable mirror,
while still authenticating that the downloaded bits are correct.
And the index service makes it easy for mirrors, godoc.org,
and any other similar sites to keep up with all the great new
code being added to the Go ecosystem every day.
We’re excited about the future of Go modules in 2019, and we hope you are too. Happy New Year!
Go 2, here we come!
2018/11/29
Background
At GopherCon 2017, Russ Cox officially started the thought process on the next big version of Go with his talk The Future of Go (blog post). We have called this future language informally Go 2, even though we understand now that it will arrive in incremental steps rather than with a big bang and a single major release. Still, Go 2 is a useful moniker, if only to have a way to talk about that future language, so let’s keep using it for now.
A major difference between Go 1 and Go 2 is who is going to influence the design and how decisions are made. Go 1 was a small team effort with modest outside influence; Go 2 will be much more community-driven. After almost 10 years of exposure, we have learned a lot about the language and libraries that we didn’t know in the beginning, and that was only possible through feedback from the Go community.
In 2015 we introduced the proposal process to gather a specific kind of feedback: proposals for language and library changes. A committee composed of senior Go team members has been reviewing, categorizing, and deciding on incoming proposals on a regular basis. That has worked pretty well, but as part of that process we have ignored all proposals that are not backward-compatible, simply labeling them Go 2 instead. In 2017 we also stopped making any kind of incremental backward-compatible language changes, however small, in favor of a more comprehensive plan that takes the bigger picture of Go 2 into account.
It is now time to act on the Go 2 proposals, but to do this we first need a plan.
Status
At the time of writing, there are around 120 open issues labeled Go 2 proposal. Each of them proposes a significant library or language change, often one that does not satisfy the existing Go 1 compatibility guarantee. Ian Lance Taylor and I have been working through these proposals and categorized them (Go2Cleanup, NeedsDecision, etc.) to get an idea of what’s there and to make it easier to proceed with them. We also merged related proposals and closed the ones which seemed clearly out of the scope of Go, or were otherwise unactionable.
Ideas from the remaining proposals will likely influence Go 2’s libraries and languages. Two major themes have emerged early on: support for better error handling, and generics. Draft designs for these two areas have been published at this year’s GopherCon, and more exploration is needed.
But what about the rest? We are constrained by the fact that we now have millions of Go programmers and a large body of Go code, and we need to bring it all along, lest we risk a split ecosystem. That means we cannot make many changes, and the changes we are going to make need to be chosen carefully. To make progress, we are implementing a new proposal evaluation process for these significant potential changes.
Proposal evaluation process
The purpose of the proposal evaluation process is to collect feedback on a small number of select proposals such that a final decision can be made. The process runs more or less in parallel to a release cycle and consists of the following steps:
1. Proposal selection. The Go team selects a small number of Go 2 proposals that seem worth considering for acceptance, without making a final decision. See below for more on the selection criteria.
2. Proposal feedback. The Go team sends out an announcement listing the selected proposals. The announcement explains to the community the tentative intent to move forward with the selected proposals and to collect feedback for each of them. This gives the community a chance to make suggestions and express concerns.
3. Implementation. Based on that feedback, the proposals are implemented. The target for these significant language and library changes is to have them ready to submit on day 1 of an upcoming release cycle.
4. Implementation feedback. During the development cycle, the Go team and community have a chance to experiment with the new features and collect further feedback.
5. Launch decision. At the end of the three month development cycle (just when starting the three month repo freeze before a release), and based on the experience and feedback gathered during the release cycle, the Go team makes the final decision about whether to ship each change. This provides an opportunity to consider whether the change has delivered the expected benefits or created any unexpected costs. Once shipped, the changes become part of the language and libraries. Excluded proposals may go back to the drawing board or may be declined for good.
With two rounds of feedback, this process is slanted towards declining proposals, which will hopefully prevent feature creep and help with keeping the language small and clean.
We can’t go through this process for each of the open Go 2 proposals, there are simply too many of them. That’s where the selection criteria come into play.
Proposal selection criteria
A proposal must at the very least:
1. address an important issue for many people,
2. have minimal impact on everybody else, and
3. come with a clear and well-understood solution.
Requirement 1 ensures that any changes we make help as many Go developers as possible (make their code more robust, easier to write, more likely to be correct, and so on), while requirement 2 ensures we are careful to hurt as few developers as possible, whether by breaking their programs or causing other churn. As a rule of thumb, we should aim to help at least ten times as many developers as we hurt with a given change. Changes that don't affect real Go usage are a net zero benefit put up against a significant implementation cost and should be avoided.
Without requirement 3 we don’t have an implementation of the proposal. For instance, we believe that some form of genericity might solve an important issue for a lot of people, but we don’t yet have a clear and well-understood solution. That’s fine, it just means that the proposal needs to go back to the drawing board before it can be considered.
Proposals
We feel that this is a good plan that should serve us well but it is important to understand that this is only a starting point. As the process is used we will discover the ways in which it fails to work well and we will refine it as needed. The critical part is that until we use it in practice we won't know how to improve it.
A safe place to start is with a small number of backward-compatible language proposals. We haven’t done language changes for a long time, so this gets us back into that mode. Also, the changes won’t require us worrying about breaking existing code, and thus they serve as a perfect trial balloon.
With all that said, we propose the following selection of Go 2 proposals for the Go 1.13 release (step 1 in the proposal evaluation process):
1. #20706 General Unicode identifiers based on Unicode TR31: This addresses an important issue for Go programmers using non-Western alphabets and should have little if any impact on anyone else. There are normalization questions which we need to answer and where community feedback will be important, but after that the implementation path is well understood. Note that identifier export rules will not be affected by this.
2. #19308, #28493 Binary integer literals and support for_ in number literals: These are relatively minor changes that seem hugely popular among many programmers. They may not quite reach the threshold of solving an “important issue” (hexadecimal numbers have worked well so far) but they bring Go up to par with most other languages in this respect and relieve a pain point for some programmers. They have minimal impact on others who don’t care about binary integer literals or number formatting, and the implementation is well understood.
3. #19113 Permit signed integers as shift counts: An estimated 38% of all non-constant shifts require an (artificial) uint conversion (see the issue for a more detailed break-down). This proposal will clean up a lot of code, get shift expressions better in sync with index expressions and the built-in functions cap and len. It will mostly have a positive impact on code. The implementation is well understood.
Next steps
With this blog post we have executed the first step and started the second step of the proposal evaluation process. It’s now up to you, the Go community, to provide feedback on the issues listed above.
For each proposal for which we have clear and approving feedback, we will move forward with the implementation (step 3 in the process). Because we want the changes implemented on the first day of the next release cycle (tentatively Feb. 1, 2019) we may start the implementation a bit early this time to leave time for two full months of feedback (Dec. 2018, Jan. 2019).
For the 3-month development cycle (Feb. to May 2019) the chosen features are implemented and available at tip and everybody will have a chance to gather experience with them. This provides another opportunity for feedback (step 4 in the process).
Finally, shortly after the repo freeze (May 1, 2019), the Go team makes the final decision whether to keep the new features for good (and include them in the Go 1 compatibility guarantee), or whether to abandon them (final step in the process).
(Since there is a real chance that a feature may need to be removed just when we freeze the repo, the implementation will need to be such that the feature can be disabled without destabilizing the rest of the system. For language changes that may mean that all feature-related code is guarded by an internal flag.)
This will be the first time that we have followed this process, hence the repo freeze will also be a good moment to reflect on the process and to adjust it if necessary. Let’s see how it goes.
Happy evaluating!
更多文章请查看索引。